
Pioneer
논문 리뷰) SCALE-Sim: Systolic CNN Accelerator Simulator 본문
ABSTRACT 요약
- Systolic Arrays는 현재(2018년 기준) 밀집 행렬 곱셈 실행에 제공하는 효율성으로 인기가 높은 연산 기질(substrates) 중 하나이다.
- 그러나 이에 대해 원리에 입각한 인사이트를 제공하기 위한 도구가 부족하다.
- 본 연구는 SCALE-SIM을 제안하며, 이는 조작 가능하며 다양한 기능을 제공한다.
I. INTRODUCTION
(생략)
II. MOTIVATION AND BACKGROUND
- DNN이 다양한 분야에 적용되면서, 그에 따른 설계의 선택폭도 넓어졌다(e.g. 엣지 디바이스부터 데이터센터까지).
- 중요한 것은 실용성으로, 각 설계에는 목적과 제약이 존재한다.
- CNN을 예로 들면, CNN의 레이어는 multi-dimensional kernel이기 때문에 이를 하드웨어에 매핑하는 여러 가지 방법이 있다.
- 반대로 하드웨어에서도 고수준 연산을 다양한 방법으로 스케줄링할 수 있다.
- 그보다 앞서서 시스템 설계 시 고려할 수 있는 요소가 굉장히 많은데, 이것들은 복잡하게 얽혀 최적의 설계를 어렵게 한다.
A. Mapping dataflows to the architecture
- MAC(Multiply-Accumulate) 연산을 하드웨어에 매핑하는 것을 data-flow라고 부른다.
- 현재 대부분의 DNN 가속기들은 하나의 data-flow를 구현한 뒤, 이를 중심으로 최적화시킨다.
- 그런데 data-flow는 주어진 CNN의 모든 레이어에 똑같이 효율적이지 않다.
- 제일 이상적인 것은 다양한 data-flows를 지원하는 가속기인데, 이는 오버헤드가 수반되고 실현은 대게 어렵다.
B. Hardware optimizations
- 최적의 data-flow가 존재하고 이에 대해 합의가 어느 정도 됐다고 가정해도, 최종 설계 결정을 위한 여러 first and second order trade-off*에 대한 선택이 존재한다.
=의역=
현재까지 분석 및 경험을 통해 DNN의 최적의 data-flow가 결정됐어도, 여전히 탐색 공간은 넓기 때문에 그걸 시뮬레이션 할 수 있는 도구는 필요하다.
*first and second order trade-off
first order: 시스템의 성능을 좌우하는 근본적인 설계 요소 (e.g. 컴퓨팅 유닛의 배치(layout))
second order: 여전히 성능에 큰 영향을 주지만 first order보다 부차적인 설계 요소 (e.g. 메모리 크기)
C. Simulators for DNN acceleration
- AI 알고리즘 배포를 가능케하는 데 주요 요구 사항은 DNN 가속기의 효율적 설계이다.
- 그럼에도 공적인 영역에서 simulation-emulation 인프라는 놀랄 정도로 부족하다.
- 이는 systolic arrays에 대해서도 마찬가지다.
III. SCALE-SIM: CNN ACCELERATOR SIMULATOR
A. Modeling Compute
- 기본적으로 convolutions와 MM(matrix-matrix) 곱셈을 시뮬레이션할 수 있다.
- MV(matrix-vector)와 VV(vector-vector)는 MM의 특수 케이스로 지원된다.
- CNN에서 사용되는 다양한 연산(e.g. Residual connection, Normalization) 중 1.의 연산만 지원하는 이유는 그것들이 네트워크의 90% 이상을 차지하기 때문이다.
- SCALE-SIM은 가속기의 연산 유닛을 systolic array*로 모델링한다.
- 일반적으로 systolic array는 정사각형 구성이지만 더 나은 형태가 존재할 수 있으므로 사용자의 입력에 따라 길이와 너비를 조절할 수 있도록 했다.
*systolic array
효율적이지만 행렬 곱셈 및 하드웨어에서 유사한 동작을 구현하기 쉬운 디자인
많은 DNN 가속기들이 systolic array에 기반한다.
systolic array는 MAC(Multiply-and-Accumulate) 또는 PE(Processing Elements)라 불리는 유닛이 2차원 구조로 함께 연결되어 있다.

출처: Wei, Xuechao et al.. (2017). Automated Systolic Array Architecture Synthesis for High Throughput CNN Inference on FPGAs.
각 PE들은 내부 레지스터에 현재 사이클의 값을 저장한다.
그와 동시에 데이터는 일반적으로 상단과 좌측, 즉 가장자리로부터 들어오며 입력된 방향으로 전파된다.
이러한 방식은 SRAM read bandwidth를 상당히 절약하고, 효율적으로 convolution 연산이 제공하는 재사용 기회를 활용할 수 있게 한다.
B. Modeling Dataflow
- Dataflow라는 명칭은 Eyeriss에서 한 것을 따왔으며 다른 명칭에 대한 명명법도 유지했다.
- Eyeriss는 Dataflow에 대해 다음 요소들을 언급했다.
- Output Stationary* (OS)
- Weight Stationary (WS)
- Input Stationary (IS)
- Row Stationary (RS)
- No Local Reuse (NLR)
*논문에 쓰인 Stationary의 의미
=원문=
The stationary term in the name of the dataflow indicates the matrix which is "pinned" to a given PE.
=의역=
dataflow에서 stationary란, 주어진 PE에 pinned된 matrix를 가리킨다.
Output Stationary (OS)
- 출력 피처 맵의 각 픽셀은 각각의 PE에 할당되어 있다.
- 각 행은 한 채널의 인접 출력 픽셀을 생성
- 각 열은 여러 채널 별 픽셀 생성
- SCALE-SIM의 dataflow는 생성된 출력이 array로부터 연산 도중 stall 없이 전송될 수 있다 가정
- 실제로는 그렇지 않을 가능성이 높음
- 그럼에도 그렇게 구현한 이유는 다른 어떠한 의존성은 배제하고, dataflow 자체만의 성능만을 평가하기 위함
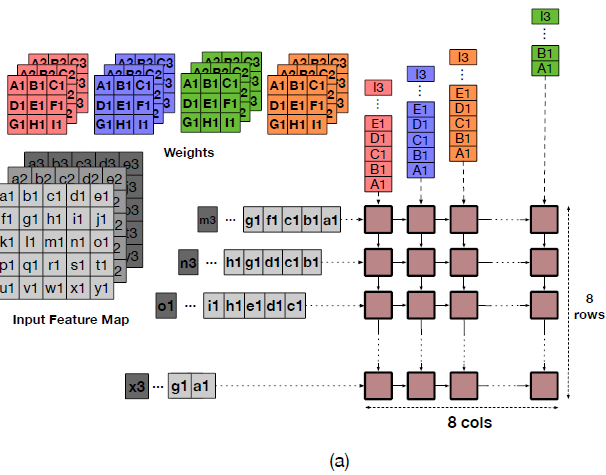
Weight Stationary (WS)
- 가중치 매트릭스의 각 요소는 MAC unit에 고유하게 매핑된다.
- 한 번 매핑된 뒤에는 해당 매트릭스가 쓰이는 연산이 끝날 때까지 교체될 수 없다.
- 매핑 과정은 두 단계를 거친다
- 각 필터마다 열을 할당한다; 채널을 할당한다
- 주어진 열의 모든 PE가 하나의 가중치 요소를 가질 때까지 하나씩 내려 보낸다.
- 이후 좌측 edge로부터 입력이 매 사이클마다 들어오고 partial sum이 계산된다.
- 이 구현을 지원하기 위한 SRAM banks의 수는 지정된 array 수의 output stationary보다 적다.
- 그러나 다중 출력 픽셀과 일치하는 partial sum은 reduced될 때까지 array 내에서 유지될 필요가 있고 이는 구현 비용을 높이게 된다.
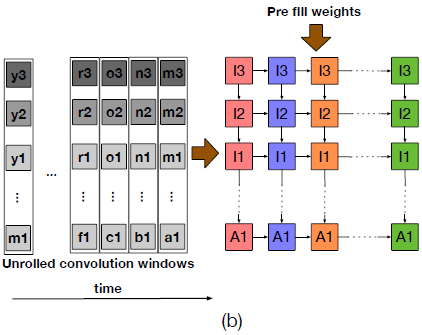
Input Stationary (IS)
- WS와 동일한 특성을 가지되, 고정되는 쪽이 IFMAP(Input Feature MAP)이다.
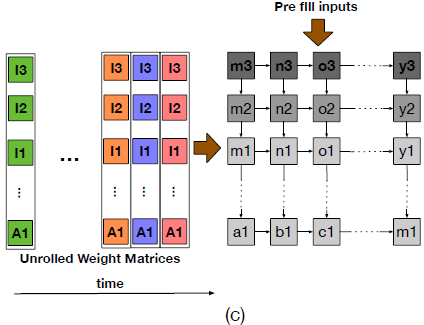
WS와 IS는 OS에 비해 SRAM bank의 수, 즉 메모리 자원이 적게 필요하다는 이점이 있다.
대신 WS와 IS가 사용이 끝날 때까지 고정되어 있어서 교체에 드는 시간이 병목으로 작용할 수 있다.
C. Modeling Memory
- CNNs은 메모리 집약적이므로 메모리 계층을 설계하는 것이 가속기의 성능을 좌우한다.
- 그러나 최적 메모리 시스템 설계는 compute array도 함께 고려해야 해서 쉽지 않다.
- SCALE-SIM은 메모리 계층을 parameterizable*하게 모델링하고 computer unit과 메모리 계층 간 공동 최적화를 가능케 한다.
- 한편 CNN은 추론 시 데이터의 spatial, temporal, spatio-temporal 재사용 패턴이 존재한다.
- 메모리 시스템 설계 시 이상적으로 working set operands를 DNN 가속기 내 compute elements의 근처에 유지시키려고 한다.
- 자연스럽게 거의 모든 가속기는 scratchpad memory 제공을 디자인한다.
- 그러나 이 scratchpad memory의 크기 결정은 쉽지 않다.
- SCALE-SIM에서는 메모리를 세 개의 논리적 파티션으로 모델링 했다.
- IFMAP
- filter matrices
- generated OFMAP
- SCALE-SIM의 모든 메모리는 SRAM 액세스 지연 시간을 숨기기 위해 이중 버퍼(double buffer)로 모델링 된다.
- working set: 여기에 담길 경우 연산에 사용됨
- idle set: 여기에 담길 경우 DMA나 memory controller를 통해 off-chip 메모리로 보내짐
*parameterizable
contigurable과 비슷한 맥락으로, 메모리 계층 구조와 그 내부 요소를 설정할 수 있다는 말
D. Modeling System Interface
- DNN 가속기를 시스템에 통합하는 것도 중요한 일이나 일부 연구에서는 간과되는 측면이 있다.
- 예를 들어, 가속기는 병렬화를 위한 다중 처리 요소를 가지더라도 각 요소에 데이터를 전달해 매 순간 모든 연산 유닛이 busy 상태이게 하는 것은 현실에선 어려울 수 있다.
- SCALE-SIM에서는 DNN 가속기가 main processor에 종속*되는 전형적인 모델 구조를 취한다.
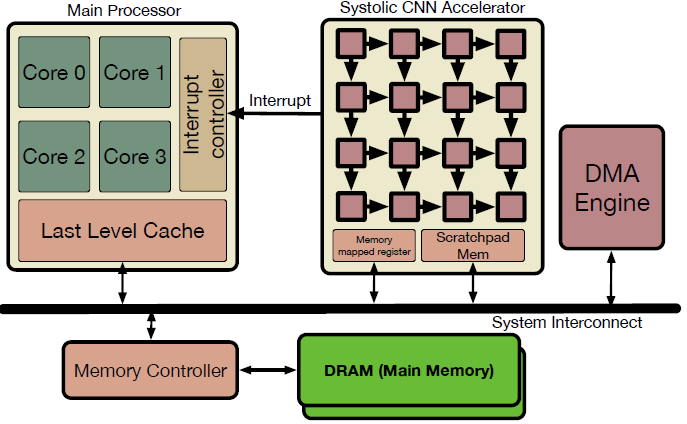
*main processor에 종속
Fig. 3.에서 Systolic CNN Accelerator로 나타난 부분은 독자적인 프로세서가 아니다.
즉, Main Processor가 명령을 전달하면 그때 동작하기 시작하는 연산 장치이다.
그 과정을 논문에 나타난대로 쓰자면
- Main Processor는 가속기의 Memory Mapped Register에 Task Descriptor를 작성한다.
- 이렇게 작업이 하달되면 Main Processor는 Context Switch를 통해 다른 작업을 수행
- 가속기는 독립적으로 메모리 장치와 통신하면서 연산 및 결과 생성
- 처리 종료 후 메모리에 결과 저장 및 Main Processor에 Interrupt 신호를 통해 알림
즉, CPU가 일을 주면 이 가속기가 일을 시작하고 그동안 CPU는 다른 작업을 처리한다.
이어서 가속기가 일이 끝나면 CPU에게 끝났다고 알리는 방식
E. Implementation
(생략)
F. User Interface
- 시뮬레이션 수행을 위해 2가지 입력이 필요
config file (Tbl. I)
- 구조에 대한 파라미터 명세 (e.g. array 크기, 메모리 크기, topology file 경로, etc.)

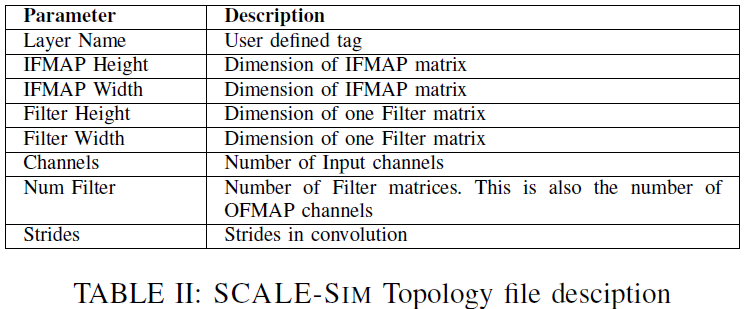
topology file (Tbl. II)
- DNN의 각 레이어에 대한 하이퍼파라미터
- CSV 파일 포맷
- 각 행은 각 레이어의 하이퍼파라미터를 의미
- 최근 모델 중에는 convolution이 병렬화된 레이어가 있는데, 이 경우에도 topology file에 적힌 순서대로 실행된다.
outputs
- 두 가지의 출력이 산출된다.
- SRAM과 DRAM의 read, write에 대한 cycle accurate traces → CSV 파일 포맷
- metrics: traces의 정보를 분석해 요약 (e.g. cycle counts, utilization, bandwidth requirements, total data transfers, etc)
IV. DESIGN INSIGHTS USING SCALE-SIM
- Systolic array는 행렬 곱셈과 기타 선형 대수 커널을 하드웨어로 구현한 것으로 잘 알려져있다.
- array 내 데이터의 통신은 인접한 요소 사이에서만 전파되며, global communication 또한 필요 없다.
- 주소 생성과 대치 작업 역시 필요치 않다.
- 예시) Google TPU, Xilinx xDNN
A. Methodology
- SCALE-SIM은 사용자가 micro-architectural parameters를 고를 수 있게 한다.
- 후술할 실험들에서는 각 parameters가 어떤 영향을 미치는지 조명할 것이다.
- 달리 명시되지 않는 한, 계산 단위의 수는 TPUv3와 동일하게 (128x128 MAC)이다.
- 단, 데이터 크기는 DNN 추론의 표준인 1바이트로 가정한다.
- operand를 위한 scratchpad memory 기본 크기는 1024 KB이며, 필터와 IFMAP 버퍼에 각 512 KB가 할당되었다.
- 워크로드로는 MLPerf를 사용했다.
B. Effect of dataflow
실험을 통해 확인하고자 한 것
- 배열 크기가 dataflow의 선택을 결정하는가? (즉, Systolic array 크기에 따른 최적 dataflow가 존재하는가?)
- 워크로드의 얼마나 많은 hyper-paremeters가 dataflow의 선택을 결정하는가?
- 고정된 dataflow 채택해서 많은 것을 놓치는가? 아니면 모든 경우에 잘 동작하는 하나의 dataflow가 있는가?
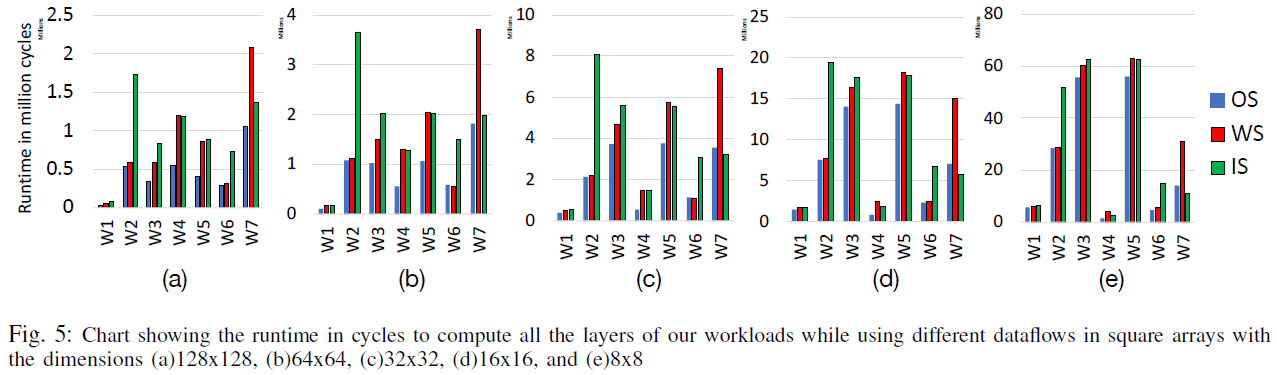
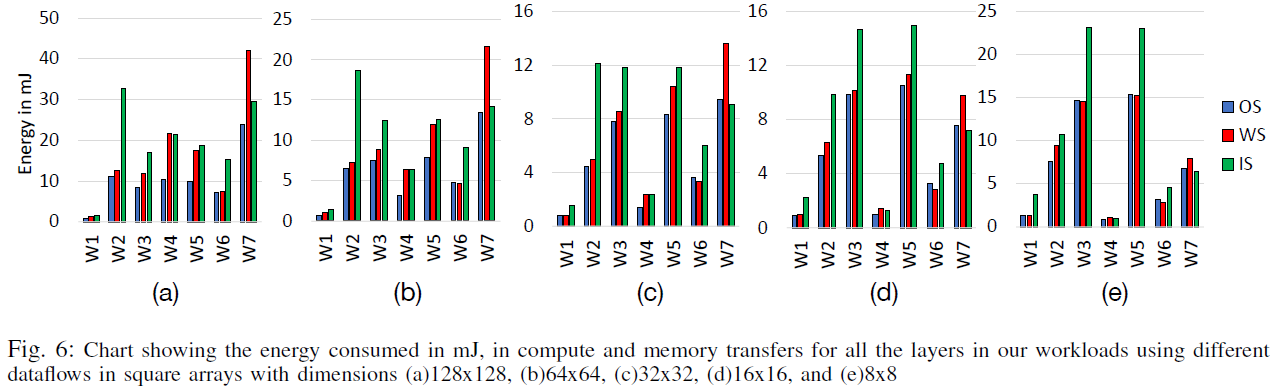
- 첫번째 물음에 대해 Fig. 5.의 W4의 각 dataflow가 가지는 흐름을 비교해보면, array 크기가 작아질 수록 IS가 WS보다 성능이 더 좋다. 따라서 특정 워크로드가 주를 이루는 문제의 경우, dataflow 선택 시 array 크기를 고려해야 한다.
- 반면 W2와 W7에 대해서는 WS와 IS가 각각 모든 경우에 대해 좋았는데, 이는 배열의 크기보다 워크로드의 특성에 더 의존적이라는 사실을 암시한다.
- 궁극적으로, '고정'된 행렬을 배열에 매핑시키는 횟수가 적을 수록 좋다.
- W7 제외하고 OS가 좋아서 웬만한 경우에 대해 OS dataflow 사용을 먼저 고려해보는 것이 좋을 것
C. Effect of Memory Sizing
- 충분한 온칩 메모리는 CNN의 재사용성과 맞물려 오프칩 액세스를 줄여 시스템 오버헤드를 줄일 수 있다.
- 그러나, 면적과 전력 소비 측면에서 고비용 리소스에 속하므로 최적 크기를 할당하는 것이 중요하다.
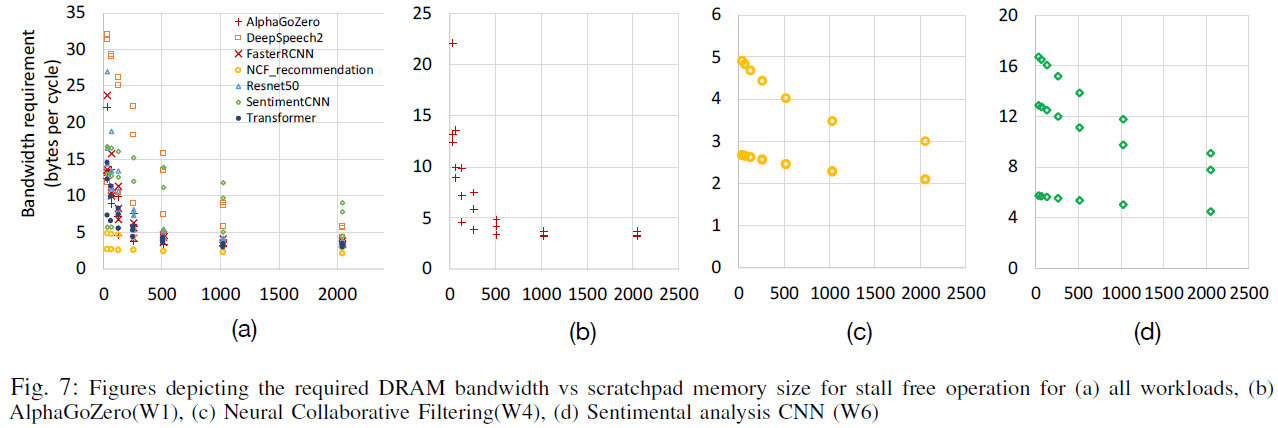
- 워크로드 별로 knee of curve(곡선이 확 꺾이는 부분)이 상이했다.
- 일반적으로 버퍼 크기가 1MB에 도달하면 return이 감소한다.
D. Effect of Shape of the array
- Systolic array의 PE 수를 갖게 유지하고 형태는 다르게 해 각 dataflow에 대한 영향을 확인한다.
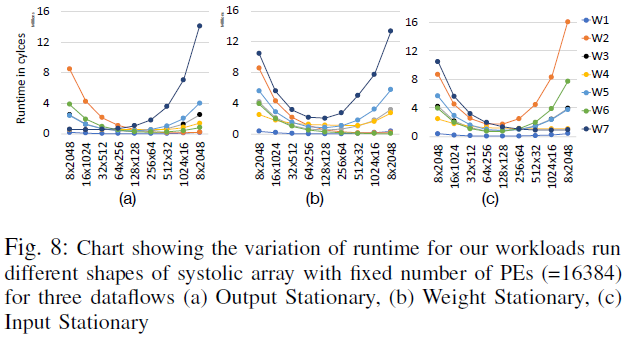
- dataflow 별로 차이가 존재하는데, 공통적인 것은 일반적으로 정사각형 형태가 제일 낫다는 것이다.
E. Scaling out vs Scaling up
- Scale-up: 배열을 크게 만들기 (e.g. TPU)
- Scale-out: 배열을 여러 개 갖기 (e.g. NVIDIA 텐서 코어)
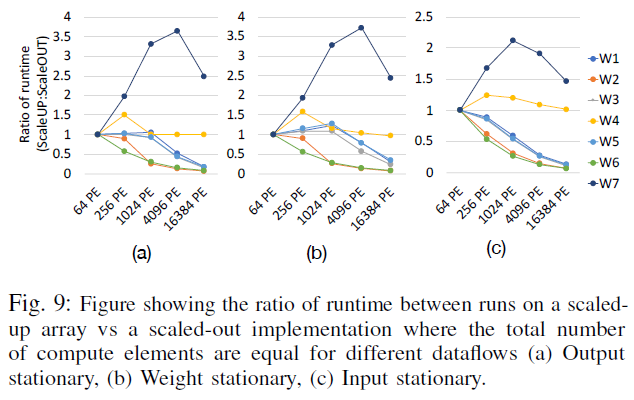
- 일반적으로 Scale-up이 dataflow에 관계 없이 더 성능이 좋음(통신 오버헤드가 줄어들어서?)
- 반면 W1의 경우는 dataflow에 관계 없이 Scale-out이 더 좋음
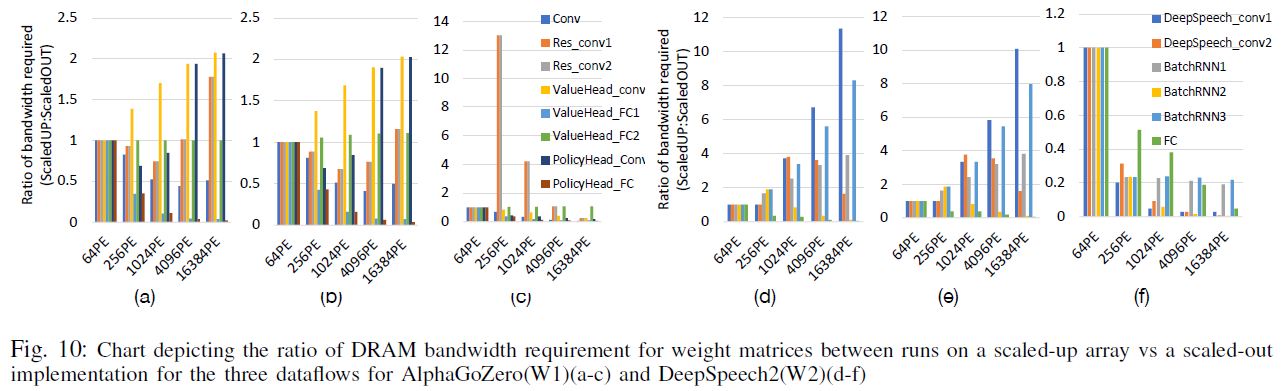
- 대부분 레이어에서 Scale-up 구현이 더 성능이 좋으나, PE 수가 늘어날 수록 Scale-out이 더 낫게 추세가 바뀜
V. RELATED WORK
(생략)
VI. CONCLUSION
- DNN의 효율적 활용을 위한 가속기 설계가 늘어나는 지금, 여전히 설계 인사이트를 얻을 수 있는 공개적인 지식과 인프라가 부족함
- 이에 대해, 본 연구는 시뮬레이션 도구를 구현 및 제공
- Systolic array-based CNN 가속기를 설계할 때 고려해야 할 파라미터의 이해를 돕기 위해 여러 가지 실험을 수행했음

